数据实时同步在当今互联网接入及相关服务中扮演着至关重要的角色,支持高并发、低延迟的数据一致性,广泛应用于电商、金融、物联网等场景。本文将全面解析数据实时同步方案,涵盖核心概念、技术选型、架构设计、代码实现及优化建议,并附上详细的架构图,旨在为开发者和架构师提供实用参考。建议收藏本文,以便随时查阅。
一、数据实时同步概述
数据实时同步是指数据在多个系统或节点间实现毫秒级或秒级的一致性更新,确保用户或应用在任何时间点访问的数据都是最新的。其核心要求包括低延迟、高可用性、数据一致性和可扩展性。在互联网接入服务中,如用户会话同步、实时推荐系统、多数据中心备份等,实时同步是基础支撑。
二、核心技术选型
实现数据实时同步的常用技术包括:
- 消息队列:如Kafka、RabbitMQ,用于异步数据传输,支持高吞吐。
- CDC(Change Data Capture):通过数据库日志(如MySQL binlog)捕获数据变更,实现准实时同步。
- 流处理框架:如Apache Flink、Spark Streaming,处理实时数据流。
- 数据库复制工具:如Debezium、Canal,用于数据库间的实时同步。
选择技术时需考虑数据量、延迟要求、系统复杂度等因素。例如,Kafka适合高吞吐场景,而Flink支持复杂事件处理。
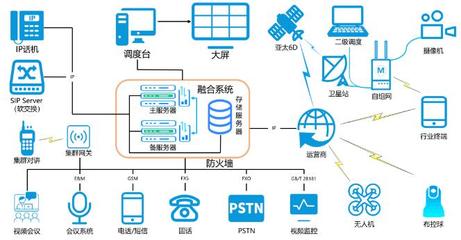
三、架构设计详解
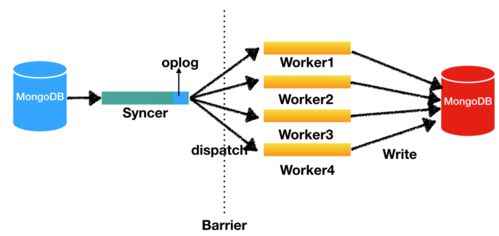
一个典型的数据实时同步架构包括数据源、采集层、处理层和目标存储。以下是基于CDC和消息队列的通用架构:
1. 数据源层:如MySQL、PostgreSQL数据库,通过binlog或WAL日志输出变更数据。
2. 采集层:使用Debezium或Canal监听数据库日志,将变更事件发布到消息队列(如Kafka)。
3. 处理层:通过流处理引擎(如Flink)消费Kafka消息,进行数据清洗、转换或聚合。
4. 目标存储层:将处理后的数据写入目标系统,如Elasticsearch用于搜索,或另一个数据库用于备份。
架构图示例:`
[数据源: MySQL] -> [CDC工具: Debezium] -> [消息队列: Kafka] -> [流处理: Flink] -> [目标: Elasticsearch/Redis]`
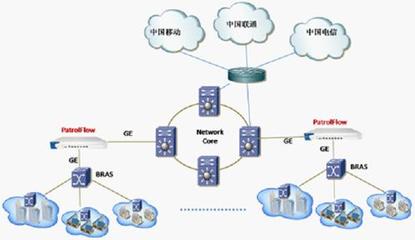
此架构支持水平扩展,通过分区和副本机制确保高可用性。在多数据中心场景中,可结合网关和负载均衡实现跨区域同步。
四、代码实现示例
以下是一个基于Java和Kafka的简单数据同步代码示例,使用Debezium捕获MySQL变更并发布到Kafka:
`java
// 使用Debezium配置MySQL连接器
public class MySQLCDCConnector {
public static void main(String[] args) {
Configuration config = Configuration.create()
.with("connector.class", "io.debezium.connector.mysql.MySqlConnector")
.with("database.hostname", "localhost")
.with("database.port", "3306")
.with("database.user", "user")
.with("database.password", "password")
.with("database.server.id", "184054")
.with("database.server.name", "my-app-connector")
.with("table.whitelist", "testdb.users")
.with("database.history.kafka.bootstrap.servers", "kafka:9092")
.with("database.history.kafka.topic", "dbhistory.test")
.build();
// 启动连接器并发布变更到Kafka主题
Engine engine = Engine.create(config);
engine.run();
}
}
// Kafka消费者处理数据(使用Spring Kafka示例)
@KafkaListener(topics = "my-app-connector.testdb.users")
public void consume(ConsumerRecord
// 解析变更数据并写入目标系统
String key = record.key();
String value = record.value();
System.out.println("Received change: " + value);
// 这里可添加逻辑,如写入Elasticsearch或另一个数据库
}`
此代码演示了如何捕获MySQL中users表的变更,并通过Kafka进行传输。在实际应用中,需添加错误处理、监控和性能优化。
五、优化与最佳实践
为确保实时同步的稳定性和效率,建议:
- 监控与告警:使用Prometheus和Grafana监控吞吐量、延迟和错误率。
- 数据一致性:采用幂等写入或分布式事务(如Saga模式)避免重复数据。
- 性能调优:调整Kafka分区数、Flink并行度,以及数据库索引。
- 容灾设计:通过多活架构或备份链路防止单点故障。
在互联网接入服务中,结合API网关和CDN可进一步提升用户体验。
六、总结与展望
数据实时同步是互联网服务的基石,本文从理论到实践全面覆盖了方案设计。随着5G和边缘计算的发展,实时同步将更注重低延迟和分布式协同。建议读者结合自身业务需求,灵活应用上述技术,并持续关注开源社区更新。收藏本文,助你在数据同步领域游刃有余。如需更详细代码或架构图,可参考GitHub相关项目或官方文档。